from libpysal import weights
import esda
import numpy
import pandas
import geopandas
import matplotlib.pyplot as plt
import seaborn
import contextily13 Spatial Regression
Regression (and prediction more generally) provides us a perfect case to examine how spatial structure can help us understand and analyze our data. In this chapter, we discuss how spatial structure can be used to both validate and improve prediction algorithms, focusing on linear regression specifically.
13.1 What is spatial regression and why should I care?
Usually, spatial structure helps regression models in one of two ways. The first (and most clear) way space can have an impact on our data is when the process generating the data is itself explicitly spatial. Here, think of something like the prices for single family homes. It’s often the case that individuals pay a premium on their house price in order to live in a better school district for the same quality house. Alternatively, homes closer to noise or chemical polluters like waste water treatment plants, recycling facilities, or wide highways, may actually be cheaper than we would otherwise anticipate. In cases like asthma incidence, the locations individuals tend to travel to throughout the day, such as their places of work or recreation, may have more impact on their health than their residential addresses. In this case, it may be necessary to use data from other sites to predict the asthma incidence at a given site. Regardless of the specific case at play, here, geography is a feature: it directly helps us make predictions about outcomes because those outcomes are obtained from geographical processes.
An alternative (and more skeptical understanding) reluctantly acknowledges geography’s instrumental value. Often, in the analysis of predictive methods and classifiers, we are interested in analyzing what we get wrong. This is common in econometrics; an analyst may be concerned that the model systematically mis-predicts some types of observations. If we know our model routinely performs poorly on a known set of observations or type of input, we might make a better model if we can account for this. Among other kinds of error diagnostics, geography provides us with an exceptionally useful embedding to assess structure in our errors. Mapping classification/prediction error can help show whether or not there are clusters of error in our data. If we know that errors tend to be larger in some areas than in other areas (or if error is “contagious” between observations), then we might be able to exploit this structure to make better predictions.
Spatial structure in our errors might arise from when geography should be an attribute somehow, but we are not sure exactly how to include it in our model. They might also arise because there is some other feature whose omission causes the spatial patterns in the error we see; if this additional feature were included, the structure would disappear. Or, it might arise from the complex interactions and interdependencies between the features that we have chosen to use as predictors, resulting in intrinsic structure in mis-prediction. Most of the predictors we use in models of social processes contain embodied spatial information: patterning intrinsic to the feature that we get for free in the model. If we intend to or not, using a spatially patterned predictor in a model can result in spatially patterned errors; using more than one can amplify this effect. Thus, regardless of whether or not the true process is explicitly geographic, additional information about the spatial relationships between our observations or more information about nearby sites can make our predictions better.
In this chapter, we build space into the traditional regression framework. We begin with a standard linear regression model, devoid of any geographical reference. From there, we formalize space and spatial relationships in three main ways: first, encoding it in exogenous variables; second, through spatial heterogeneity, or as systematic variation of outcomes across space; third, as dependence, or through the effect associated to the characteristics of spatial neighbors. Throughout, we focus on the conceptual differences each approach entails rather than on the technical details.
13.2 Data: San Diego Airbnb
To learn a little more about how regression works, we’ll examine information about Airbnb properties in San Diego, CA. This dataset contains house intrinsic characteristics, both continuous (number of beds as in beds) and categorical (type of renting or, in Airbnb jargon, property group as in the series of pg_X binary variables), but also variables that explicitly refer to the location and spatial configuration of the dataset (e.g., distance to Balboa Park, d2balboa or neighborhood id, neighborhood_cleansed).
db = geopandas.read_file("../data/airbnb/regression_db.geojson")These are the explanatory variables we will use throughout the chapter.
variable_names = [
"accommodates", # Number of people it accommodates
"bathrooms", # Number of bathrooms
"bedrooms", # Number of bedrooms
"beds", # Number of beds
# Below are binary variables, 1 True, 0 False
"rt_Private_room", # Room type: private room
"rt_Shared_room", # Room type: shared room
"pg_Condominium", # Property group: condo
"pg_House", # Property group: house
"pg_Other", # Property group: other
"pg_Townhouse", # Property group: townhouse
]13.3 Non-spatial regression, a (very) quick refresh
Before we discuss how to explicitly include space into the linear regression framework, let us show how basic regression can be carried out in Python, and how one can begin to interpret the results. By no means is this a formal and complete introduction to regression so, if that is what you are looking for, we recommend (Gelman and Hill 2006), in particular chapters 3 and 4, which provide a fantastic, non-spatial introduction.
The core idea of linear regression is to explain the variation in a given (dependent) variable as a linear function of a collection of other (explanatory) variables. For example, in our case, we may want to express the price of a house as a function of the number of bedrooms it has and whether it is a condominium or not. At the individual level, we can express this as:
\[ P_i = \alpha + \sum_k \mathbf{X}_{ik}\beta_k + \epsilon_i \]
where \(P_i\) is the Airbnb price of house \(i\), and \(X\) is a set of covariates that we use to explain such price (e.g., No. of bedrooms and condominium binary variable). \(\beta\) is a vector of parameters that give us information about in which way and to what extent each variable is related to the price, and \(\alpha\), the constant term, is the average house price when all the other variables are zero. The term \(\epsilon_i\) is usually referred to as “error” and captures elements that influence the price of a house but are not included in \(X\). We can also express this relation in matrix form, excluding sub-indices for \(i\), which yields:
\[ P = \alpha + \mathbf{X}\beta + \epsilon \]
A regression can be seen as a multivariate extension of bivariate correlations. Indeed, one way to interpret the \(\beta_k\) coefficients in the equation above is as the degree of correlation between the explanatory variable \(k\) and the dependent variable, keeping all the other explanatory variables constant. When one calculates bivariate correlations, the coefficient of a variable is picking up the correlation between the variables, but it is also subsuming into it variation associated with other correlated variables – also called confounding factors. Regression allows us to isolate the distinct effect that a single variable has on the dependent one, once we control for those other variables.
Practically speaking, linear regressions in Python are rather streamlined and easy to work with. There are also several packages which will run them (e.g., statsmodels, scikit-learn, pysal). We will import the spreg module in Pysal:
import spregIn the context of this chapter, it makes sense to start with spreg, as that is the only library that will allow us to move into explicitly spatial econometric models. To fit the model specified in the equation above with \(X\) as the list defined, using ordinary least squares (OLS), we only need the following line of code:
# Fit OLS model
m1 = spreg.OLS(
# Dependent variable
db[["log_price"]].values,
# Independent variables
db[variable_names].values,
# Dependent variable name
name_y="log_price",
# Independent variable name
name_x=variable_names,
)We use the command OLS, part of the spreg sub-package, and specify the dependent variable (the log of the price, so we can interpret results in terms of percentage change) and the explanatory ones. Note that both objects need to be arrays, so we extract them from the pandas.DataFrame object using .values.
In order to inspect the results of the model, we can print the summary attribute:
print(m1.summary)REGRESSION RESULTS
------------------
SUMMARY OF OUTPUT: ORDINARY LEAST SQUARES
------------------------------------------------------------------------------------
Data set : unknown
Weights matrix : None
Dependent Variable : log_price Number of Observations: 6110
Mean dependent var : 4.9958 Number of Variables : 11
S.D. dependent var : 0.8072 Degrees of Freedom : 6099
R-squared : 0.6683
Adjusted R-squared : 0.6678
Sum squared residual: 1320.15 F-statistic : 1229.0564
Sigma-square : 0.216 Prob(F-statistic) : 0
S.E. of regression : 0.465 Log likelihood : -3988.895
Sigma-square ML : 0.216 Akaike info criterion : 7999.790
S.E of regression ML: 0.4648 Schwarz criterion : 8073.685
------------------------------------------------------------------------------------
Variable Coefficient Std.Error t-Statistic Probability
------------------------------------------------------------------------------------
CONSTANT 4.38838 0.01611 272.32178 0.00000
accommodates 0.08345 0.00508 16.43363 0.00000
bathrooms 0.19238 0.01097 17.54198 0.00000
bedrooms 0.15252 0.01113 13.70092 0.00000
beds -0.04172 0.00694 -6.01344 0.00000
rt_Private_room -0.55069 0.01590 -34.62448 0.00000
rt_Shared_room -1.23831 0.03843 -32.21990 0.00000
pg_Condominium 0.14363 0.02215 6.48465 0.00000
pg_House -0.01049 0.01453 -0.72184 0.47042
pg_Other 0.14115 0.02280 6.19056 0.00000
pg_Townhouse -0.04167 0.03428 -1.21573 0.22413
------------------------------------------------------------------------------------
REGRESSION DIAGNOSTICS
MULTICOLLINEARITY CONDITION NUMBER 11.964
TEST ON NORMALITY OF ERRORS
TEST DF VALUE PROB
Jarque-Bera 2 2671.611 0.0000
DIAGNOSTICS FOR HETEROSKEDASTICITY
RANDOM COEFFICIENTS
TEST DF VALUE PROB
Breusch-Pagan test 10 322.532 0.0000
Koenker-Bassett test 10 135.581 0.0000
================================ END OF REPORT =====================================A full detailed explanation of the output is beyond the scope of this chapter, so we will focus on the relevant bits for our main purpose. This is concentrated on the Coefficients section, which gives us the estimates for \(\beta_k\) in our model. In other words, these numbers express the relationship between each explanatory variable and the dependent one, once the effect of confounding factors has been accounted for. Keep in mind however that regression is no magic; we are only discounting the effect of confounding factors that we include in the model, not of all potentially confounding factors.
Results are largely as expected: houses tend to be significantly more expensive if they accommodate more people (accommodates), if they have more bathrooms and bedrooms, and if they are a condominium or part of the “other” category of house type. Conversely, given a number of rooms, houses with more beds (i.e., listings that are more “crowded”) tend to go for cheaper, as it is the case for properties where one does not rent the entire house but only a room (rt_Private_room) or even shares it (rt_Shared_room). Of course, you might conceptually doubt the assumption that it is possible to arbitrarily change the number of beds within an Airbnb without eventually changing the number of people it accommodates, but methods to address these concerns using interaction effects won’t be discussed here.
13.4 Bringing space into the regression framework
There are many different ways that spatial structure shows up in our models, predictions, and our data, even if we do not explicitly intend to study it. Fortunately, there are nearly as many techniques, called spatial regression methods, that are designed to handle these sorts of structures. Spatial regression is about explicitly introducing space or geographical context into the statistical framework of a regression. Conceptually, we want to introduce space into our model whenever we think it plays an important role in the process we are interested in, or when space can act as a reasonable proxy for other factors that we cannot but should include in our model. As an example of the former, we can imagine how houses at the seafront are probably more expensive than those in the second row, given their better views. To illustrate the latter, we can think of how the character of a neighborhood is important in determining the price of a house; however, it is very hard to identify and quantify “character” per se, although it might be easier to get at its spatial variation, hence a case of space as a proxy.
Spatial regression is a large field of development in the econometrics and statistics literatures. In this brief introduction, we will consider two related but very different processes that give rise to spatial effects: spatial heterogeneity and spatial dependence. Before diving into them, we begin with another approach that introduces space in a regression model without modifying the model itself but rather creates spatially explicit independent variables. For more rigorous treatments of the topics introduced here, we refer you to (Anselin 2003; Anselin and Rey 2014; Gelman and Hill 2006).
13.4.1 Spatial feature engineering: proximity variables
Using geographic information to “construct” new data is a common approach to bring in spatial information into data analysis. Often, this reflects the fact that processes are not the same everywhere in the map of analysis, or that geographical information may be useful to predict our outcome of interest. In this section, we will briefly present how to insert spatial features, or \(X\) variables that are constructed from geographical relationships, in a standard linear model. We discuss spatial feature engineering extensively in Chapter 12, though, and the depth and extent of spatial feature engineering is difficult to over-state. Rather than detail, this section will show how spatially explicit variables you engineer can be “plugged” into a model to improve its performance or help you explain the underlying process of interest with more accuracy.
One relevant proximity-driven variable that could influence our San Diego model is based on the listings proximity to Balboa Park. A common tourist destination, Balboa Park is a central recreation hub for the city of San Diego, containing many museums and the San Diego Zoo. Thus, it could be the case that people searching for Airbnbs in San Diego are willing to pay a premium to live closer to the park. If this were true and we omitted this from our model, we may indeed see a significant spatial pattern caused by this distance decay effect.
Therefore, this is sometimes called a spatially patterned omitted covariate: geographic information our model needs to make good predictions which we have left out of our model. Therefore, let’s build a new model containing this distance to Balboa Park covariate. First, though, it helps to visualize (Fig. XXX5XXX) the structure of this distance covariate itself:
ax = db.plot("d2balboa", marker=".", s=5)
contextily.add_basemap(ax, crs=db.crs)
ax.set_axis_off();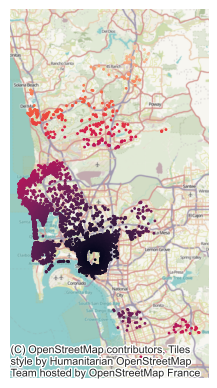
To run a linear model that includes the additional variable of distance to the park, we add the name to the list of variables we included originally:
balboa_names = variable_names + ["d2balboa"]And then fit the model using the OLS class in Pysal’s spreg:
m2 = spreg.OLS(
db[["log_price"]].values,
db[balboa_names].values,
name_y="log_price",
name_x=balboa_names,
)When you inspect the regression diagnostics and output, you see that this covariate is not quite as helpful as we might anticipate:
pandas.DataFrame(
[[m1.r2, m1.ar2], [m2.r2, m2.ar2]],
index=["M1", "M2"],
columns=["R2", "Adj. R2"],
)| R2 | Adj. R2 | |
|---|---|---|
| M1 | 0.668345 | 0.667801 |
| M2 | 0.668502 | 0.667904 |
It is not statistically significant at conventional significance levels, the model fit does not substantially change:
# Set up table of regression coefficients
pandas.DataFrame(
{
# Pull out regression coefficients and
# flatten as they are returned as Nx1 array
"Coeff.": m2.betas.flatten(),
# Pull out and flatten standard errors
"Std. Error": m2.std_err.flatten(),
# Pull out P-values from t-stat object
"P-Value": [i[1] for i in m2.t_stat],
},
index=m2.name_x,
)| Coeff. | Std. Error | P-Value | |
|---|---|---|---|
| CONSTANT | 4.379624 | 0.016915 | 0.000000e+00 |
| accommodates | 0.083644 | 0.005079 | 1.156896e-59 |
| bathrooms | 0.190791 | 0.011005 | 9.120139e-66 |
| bedrooms | 0.150746 | 0.011179 | 7.418035e-41 |
| beds | -0.041476 | 0.006939 | 2.394322e-09 |
| rt_Private_room | -0.552996 | 0.015960 | 2.680270e-240 |
| rt_Shared_room | -1.235521 | 0.038462 | 2.586867e-209 |
| pg_Condominium | 0.140459 | 0.022225 | 2.803765e-10 |
| pg_House | -0.013302 | 0.014623 | 3.630396e-01 |
| pg_Other | 0.141176 | 0.022798 | 6.309880e-10 |
| pg_Townhouse | -0.045784 | 0.034356 | 1.826992e-01 |
| d2balboa | 0.001645 | 0.000967 | 8.902052e-02 |
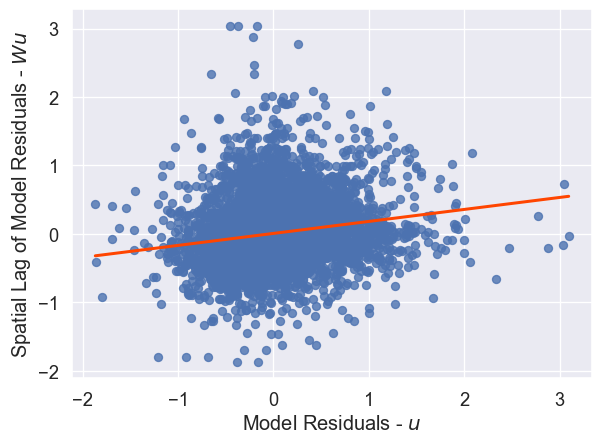
And, there still appears to be spatial structure in our model’s errors, as we can see in Figure XXX6XXX, generated by the code below:
lag_residual = weights.spatial_lag.lag_spatial(knn, m2.u)
ax = seaborn.regplot(
x=m2.u.flatten(),
y=lag_residual.flatten(),
line_kws=dict(color="orangered"),
ci=None,
)
ax.set_xlabel("Residuals ($u$)")
ax.set_ylabel("Spatial lag of residuals ($Wu$)");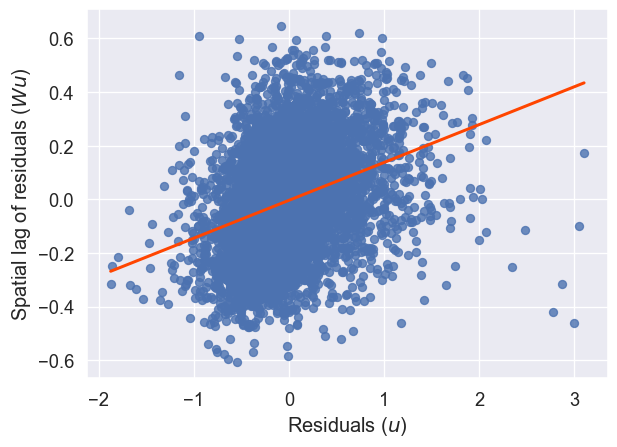
Finally, the distance to Balboa Park variable does not fit our theory about how distance to amenity should affect the price of an Airbnb; the coefficient estimate is positive, meaning that people are paying a premium to be further from Balboa Park. We will revisit this result later on, when we consider spatial heterogeneity and will be able to shed some light on this. Further, the next chapter is an extensive treatment of spatial fixed effects, presenting many more spatial feature engineering methods. Here, we have only showed how to include these engineered features in a standard linear modeling framework.
13.4.2 Spatial heterogeneity
So far we have assumed that our proximity variable might stand in for a difficult-to-measure premium individuals pay when they’re close to a recreational zone (a park in this case). Our approach in that case was to incorporate space through a very specific channel, that is the distance to an amenity we thought might be influencing the final price. However, not all neighborhoods have the same house prices; some neighborhoods may be systematically more expensive than others, regardless of their proximity to Balboa Park. If this is our case, we need some way to account for the fact that each neighborhood may experience these kinds of gestalt, unique effects. One way to do this is by capturing spatial heterogeneity (SH). At its most basic, spatial heterogeneity means that parts of the model may vary systematically with geography, change in different places. For example, changes to the intercept, \(\alpha\), may reflect the fact that different areas have different baseline exposures to a given process. Changes to the slope terms, \(\beta\), may indicate some kind of geographical mediating factor that makes the relationship between the independent and dependent variables vary across space, such as when a governmental policy is not consistently applied across jurisdictions. Finally, changes to the variance of the residuals, commonly denoted \(\sigma^2\), can introduce spatial heteroskedasticity. We deal with the first two in this section.
13.4.2.1 Spatial fixed effects
The literature commonly refers to geographic variations of \(\alpha\) as “spatial fixed effects (FE)”. To illustrate them, let us consider the house price example from the previous section. Sometimes, spatial fixed effects are said to capture “space as a proxy”, in that we know the outcome varies over space, we (hope to) know the pattern it follows (in our case, by neighborhood) and we can thus incorporate that knowledge into the model by letting \(\alpha\) vary accordingly. The rationale goes as follows. Given we are only including a few explanatory variables in the model, it is likely we are missing some important factors that play a role at determining the price at which a house is sold. Some of them, however, are likely to vary systematically over space (e.g., different neighborhood characteristics). If that is the case, we can control for those unobserved factors by using traditional binary variables but basing their creation on a spatial rule. For example, let us include a binary variable for every neighborhood, indicating whether a given house is located within such area (1) or not (0). Mathematically, we are now fitting the following equation:
\[ \log{P_i} = \alpha_r + \sum_k \mathbf{X}_{ik}\beta_k + \epsilon_i \]
where the main difference is that we are now allowing the constant term, \(\alpha\), to vary by neighborhood \(r\), \(\alpha_r\).
Programmatically, we will show two different ways we can estimate this: one, using statsmodels; and two, with spreg. First, we will use statsmodels, the econometrician’s toolbox in Python.
import statsmodels.formula.api as smThis package provides a formula-like API, which allows us to express the equation we wish to estimate directly:
f = (
"log_price ~ "
+ " + ".join(variable_names)
+ " + neighborhood - 1"
)
print(f)log_price ~ accommodates + bathrooms + bedrooms + beds + rt_Private_room + rt_Shared_room + pg_Condominium + pg_House + pg_Other + pg_Townhouse + neighborhood - 1The tilde operator in this statement is usually read as “log price is a function of …”, to account for the fact that many different model specifications can be fit according to that functional relationship between log_price and our covariate list. Critically, note that the trailing -1 term means that we are fitting this model without an intercept term. This is necessary, since including an intercept term alongside unique means for every neighborhood would make the underlying system of equations underspecified.
Using this expression, we can estimate the unique effects of each neighborhood, fitting the model in statsmodels (note how the specification of the model, formula and data is separated from the fitting step):
m3 = sm.ols(f, data=db).fit()We could rely on the summary2() method to print a similar summary report from the regression but, given it is a lengthy one in this case, we will illustrate how you can extract the spatial fixed effects into a table for display.
# Store variable names for all the spatial fixed effects
sfe_names = [i for i in m3.params.index if "neighborhood[" in i]
# Create table
pandas.DataFrame(
{
"Coef.": m3.params[sfe_names],
"Std. Error": m3.bse[sfe_names],
"P-Value": m3.pvalues[sfe_names],
}
)| Coef. | Std. Error | P-Value | |
|---|---|---|---|
| neighborhood[Balboa Park] | 4.280766 | 0.033292 | 0.0 |
| neighborhood[Bay Ho] | 4.198251 | 0.076878 | 0.0 |
| neighborhood[Bay Park] | 4.329223 | 0.050987 | 0.0 |
| neighborhood[Carmel Valley] | 4.389261 | 0.056553 | 0.0 |
| neighborhood[City Heights West] | 4.053518 | 0.058378 | 0.0 |
| neighborhood[Clairemont Mesa] | 4.095259 | 0.047699 | 0.0 |
| neighborhood[College Area] | 4.033697 | 0.058258 | 0.0 |
| neighborhood[Core] | 4.726186 | 0.052643 | 0.0 |
| neighborhood[Cortez Hill] | 4.608090 | 0.051526 | 0.0 |
| neighborhood[Del Mar Heights] | 4.496910 | 0.054337 | 0.0 |
| neighborhood[East Village] | 4.545469 | 0.029373 | 0.0 |
| neighborhood[Gaslamp Quarter] | 4.775799 | 0.047304 | 0.0 |
| neighborhood[Grant Hill] | 4.306742 | 0.052365 | 0.0 |
| neighborhood[Grantville] | 4.053298 | 0.071396 | 0.0 |
| neighborhood[Kensington] | 4.302671 | 0.077176 | 0.0 |
| neighborhood[La Jolla] | 4.682084 | 0.025809 | 0.0 |
| neighborhood[La Jolla Village] | 4.330311 | 0.077237 | 0.0 |
| neighborhood[Linda Vista] | 4.191149 | 0.056916 | 0.0 |
| neighborhood[Little Italy] | 4.666742 | 0.046838 | 0.0 |
| neighborhood[Loma Portal] | 4.301909 | 0.033236 | 0.0 |
| neighborhood[Marina] | 4.558298 | 0.047994 | 0.0 |
| neighborhood[Midtown] | 4.366661 | 0.028394 | 0.0 |
| neighborhood[Midtown District] | 4.584938 | 0.065087 | 0.0 |
| neighborhood[Mira Mesa] | 3.989562 | 0.056101 | 0.0 |
| neighborhood[Mission Bay] | 4.515479 | 0.022422 | 0.0 |
| neighborhood[Mission Valley] | 4.275960 | 0.074231 | 0.0 |
| neighborhood[Moreno Mission] | 4.400942 | 0.056730 | 0.0 |
| neighborhood[Normal Heights] | 4.097400 | 0.049022 | 0.0 |
| neighborhood[North Clairemont] | 3.984440 | 0.069149 | 0.0 |
| neighborhood[North Hills] | 4.253425 | 0.025478 | 0.0 |
| neighborhood[Northwest] | 4.173752 | 0.069728 | 0.0 |
| neighborhood[Ocean Beach] | 4.437164 | 0.030088 | 0.0 |
| neighborhood[Old Town] | 4.420160 | 0.041893 | 0.0 |
| neighborhood[Otay Ranch] | 4.185941 | 0.081597 | 0.0 |
| neighborhood[Pacific Beach] | 4.438829 | 0.022417 | 0.0 |
| neighborhood[Park West] | 4.440907 | 0.044768 | 0.0 |
| neighborhood[Rancho Bernadino] | 4.180906 | 0.072010 | 0.0 |
| neighborhood[Rancho Penasquitos] | 4.162428 | 0.061776 | 0.0 |
| neighborhood[Roseville] | 4.386992 | 0.058623 | 0.0 |
| neighborhood[San Carlos] | 4.334991 | 0.083040 | 0.0 |
| neighborhood[Scripps Ranch] | 4.082380 | 0.076244 | 0.0 |
| neighborhood[Serra Mesa] | 4.312967 | 0.059925 | 0.0 |
| neighborhood[South Park] | 4.225311 | 0.053643 | 0.0 |
| neighborhood[University City] | 4.193718 | 0.036965 | 0.0 |
| neighborhood[West University Heights] | 4.297672 | 0.043134 | 0.0 |
The approach above shows how spatial FE are a particular case of a linear regression with a categorical variable. Neighborhood membership is modeled using binary dummy variables. Thanks to the formula grammar used in statsmodels, we can express the model abstractly, and Python parses it, appropriately creating binary variables as required.
The second approach leverages spreg Regimes functionality. We will see regimes below but, for now, think of them as a generalization of spatial fixed effects where not only \(\alpha\) can vary. This framework allows the user to specify which variables are to be estimated separately for each group. In this case, instead of describing the model in a formula, we need to pass each element of the model as separate arguments.
# spreg spatial fixed effect implementation
m4 = spreg.OLS_Regimes(
# Dependent variable
db[["log_price"]].values,
# Independent variables
db[variable_names].values,
# Variable specifying neighborhood membership
db["neighborhood"].tolist(),
# Allow the constant term to vary by group/regime
constant_regi="many",
# Variables to be allowed to vary (True) or kept
# constant (False). Here we set all to False
cols2regi=[False] * len(variable_names),
# Allow separate sigma coefficients to be estimated
# by regime (False so a single sigma)
regime_err_sep=False,
# Dependent variable name
name_y="log_price",
# Independent variables names
name_x=variable_names,
)Similarly as above, we could rely on the summary attribute to print a report with all the results computed. For simplicity here, we will only confirm that, to the 12th decimal, the parameters estimated are indeed the same as those we get from statsmodels:
import numpy
numpy.round(m4.betas.flatten() - m3.params.values, decimals=12)array([ 0., -0., 0., 0., 0., 0., 0., 0., 0., -0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., -0., 0., -0., 0., -0., -0., 0.,
0., 0., 0.])Econometrically speaking, what the neighborhood FEs we have introduced imply is that, instead of comparing all house prices across San Diego as equal, we only derive variation from within each postcode. Remember that the interpretation of \(\beta_k\) is the effect of variable \(k\), given all the other explanatory variables included remain constant. By including a single variable for each area, we are effectively forcing the model to compare as equal only house prices that share the same value for each variable; or, in other words, only houses located within the same area. Introducing FE affords a higher degree of isolation of the effects of the variables we introduce in the model because we can control for unobserved effects that align spatially with the distribution of the FE introduced (by neighborhood, in our case). To make a map of neighborhood fixed effects, we need to process the results from our model slightly.
First, we extract only the effects pertaining to the neighborhoods:
neighborhood_effects = m3.params.filter(like="neighborhood")
neighborhood_effects.head()neighborhood[Balboa Park] 4.280766
neighborhood[Bay Ho] 4.198251
neighborhood[Bay Park] 4.329223
neighborhood[Carmel Valley] 4.389261
neighborhood[City Heights West] 4.053518
dtype: float64Then, we need to extract just the neighborhood name from the index of this Series. A simple way to do this is to strip all the characters that come before and after our neighborhood names:
# Create a sequence with the variable names without
# `neighborhood[` and `]`
stripped = neighborhood_effects.index.str.strip(
"neighborhood["
).str.strip("]")
# Reindex the neighborhood_effects Series on clean names
neighborhood_effects.index = stripped
# Convert Series to DataFrame
neighborhood_effects = neighborhood_effects.to_frame("fixed_effect")
# Print top of table
neighborhood_effects.head()| fixed_effect | |
|---|---|
| Balboa Park | 4.280766 |
| Bay Ho | 4.198251 |
| Bay Park | 4.329223 |
| Carmel Valley | 4.389261 |
| City Heights West | 4.053518 |
Good, we’re back to our raw neighborhood names. These allow us to join it to an auxillary file with neighborhood boundaries that is indexed on the same names. Let’s read the boundaries first:
sd_path = "../data/airbnb/neighbourhoods.geojson"
neighborhoods = geopandas.read_file(sd_path)And we can then merge the spatial FE and plot them on a map (Fig. XXX7XXX):
# Plot base layer with all neighborhoods in grey
ax = neighborhoods.plot(
color="k", linewidth=0, alpha=0.5, figsize=(12, 6)
)
# Merge SFE estimates (note not every polygon
# receives an estimate since not every polygon
# contains Airbnb properties)
neighborhoods.merge(
neighborhood_effects,
how="left",
left_on="neighbourhood",
right_index=True
# Drop polygons without a SFE estimate
).dropna(
subset=["fixed_effect"]
# Plot quantile choropleth
).plot(
"fixed_effect", # Variable to display
scheme="quantiles", # Choropleth scheme
k=7, # No. of classes in the choropleth
linewidth=0.1, # Polygon border width
cmap="viridis", # Color scheme
ax=ax, # Axis to draw on
)
# Add basemap
contextily.add_basemap(
ax,
crs=neighborhoods.crs,
source=contextily.providers.CartoDB.PositronNoLabels,
)
# Remove axis
ax.set_axis_off()
# Display
plt.show()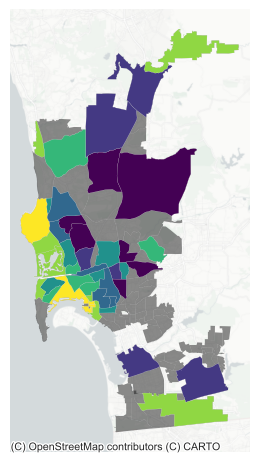
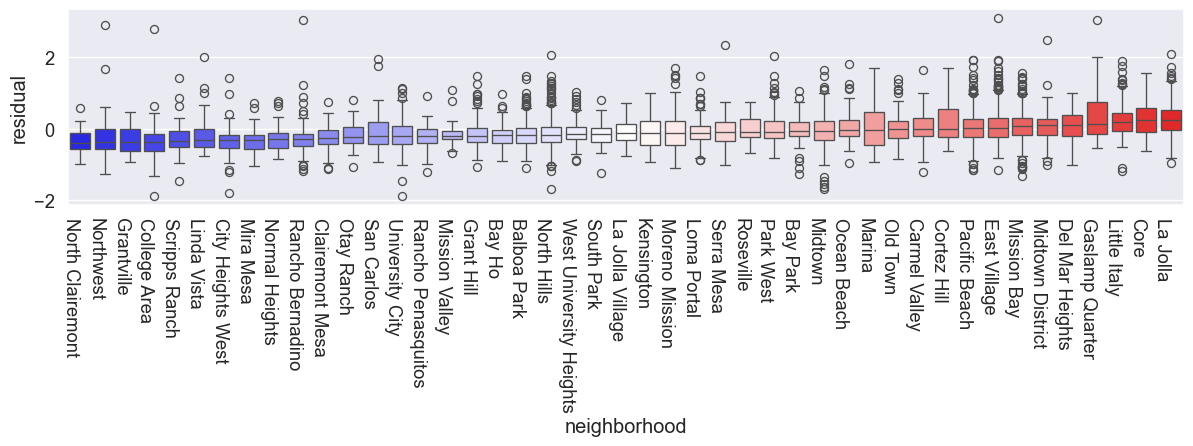
We can see a clear spatial structure in the SFE estimates. The most expensive neighborhoods tend to be located near the coast, while the cheapest ones are more inland.
13.4.2.2 Spatial regimes
At the core of estimating spatial FEs is the idea that, instead of assuming the dependent variable behaves uniformly over space, there are systematic effects following a geographical pattern that affect its behavior. In other words, spatial FEs introduce econometrically the notion of spatial heterogeneity. They do this in the simplest possible form: by allowing the constant term to vary geographically. The other elements of the regression are left untouched and hence apply uniformly across space. The idea of spatial regimes (SRs) is to generalize the spatial FE approach to allow not only the constant term to vary but also any other explanatory variable. This implies that the equation we will be estimating is:
\[ \log{P_i} = \alpha_r + \sum_k \mathbf{X}_{ki}\beta_{k-r} + \epsilon_i \]
where we are not only allowing the constant term to vary by region (\(\alpha_r\)), but also every other parameter (\(\beta_{k-r}\)).
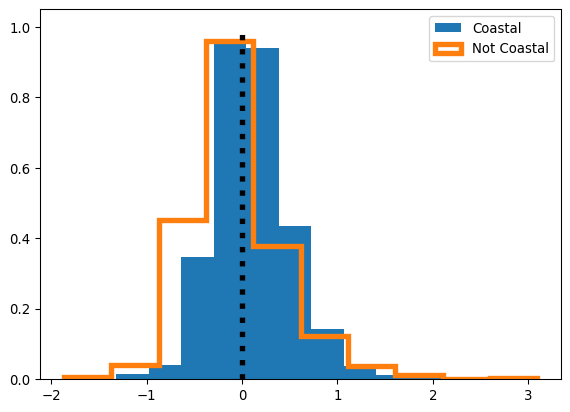
To illustrate this approach, we will use the “spatial differentiator” of whether a house is in a coastal neighborhood or not (coastal_neig) to define the regimes. The rationale behind this choice is that renting a house close to the ocean might be a strong enough pull that people might be willing to pay at different rates for each of the house’s characteristics.
To implement this in Python, we use the OLS_Regimes class in spreg, which does most of the heavy lifting for us:
# Pysal spatial regimes implementation
m5 = spreg.OLS_Regimes(
# Dependent variable
db[["log_price"]].values,
# Independent variables
db[variable_names].values,
# Variable specifying neighborhood membership
db["coastal"].tolist(),
# Allow the constant term to vary by group/regime
constant_regi="many",
# Allow separate sigma coefficients to be estimated
# by regime (False so a single sigma)
regime_err_sep=False,
# Dependent variable name
name_y="log_price",
# Independent variables names
name_x=variable_names,
)The result can be explored and interpreted similarly to the previous ones. If you inspect the summary attribute, you will find the parameters for each variable mostly conform to what you would expect, across both regimes. To compare them, we can plot them side-by-side on a bespoke table:
# Results table
res = pandas.DataFrame(
{
# Pull out regression coefficients and
# flatten as they are returned as Nx1 array
"Coeff.": m5.betas.flatten(),
# Pull out and flatten standard errors
"Std. Error": m5.std_err.flatten(),
# Pull out P-values from t-stat object
"P-Value": [i[1] for i in m5.t_stat],
},
index=m5.name_x,
)
# Coastal regime
## Extract variables for the coastal regime
coastal = [i for i in res.index if "1_" in i]
## Subset results to coastal and remove the 1_ underscore
coastal = res.loc[coastal, :].rename(lambda i: i.replace("1_", ""))
## Build multi-index column names
coastal.columns = pandas.MultiIndex.from_product(
[["Coastal"], coastal.columns]
)
# Non-coastal model
## Extract variables for the non-coastal regime
ncoastal = [i for i in res.index if "0_" in i]
## Subset results to non-coastal and remove the 0_ underscore
ncoastal = res.loc[ncoastal, :].rename(lambda i: i.replace("0_", ""))
## Build multi-index column names
ncoastal.columns = pandas.MultiIndex.from_product(
[["Non-coastal"], ncoastal.columns]
)
# Concat both models
pandas.concat([coastal, ncoastal], axis=1)| Coastal | Non-coastal | |||||
|---|---|---|---|---|---|---|
| Coeff. | Std. Error | P-Value | Coeff. | Std. Error | P-Value | |
| CONSTANT | 4.479904 | 0.025094 | 0.000000e+00 | 4.407242 | 0.021516 | 0.000000e+00 |
| accommodates | 0.048464 | 0.007881 | 8.253761e-10 | 0.090186 | 0.006474 | 1.893020e-43 |
| bathrooms | 0.247478 | 0.016566 | 1.381278e-49 | 0.143376 | 0.014268 | 1.418804e-23 |
| bedrooms | 0.189740 | 0.017923 | 5.783965e-26 | 0.112963 | 0.013827 | 3.731742e-16 |
| beds | -0.050608 | 0.010743 | 2.522348e-06 | -0.026272 | 0.008838 | 2.964354e-03 |
| rt_Private_room | -0.558628 | 0.028312 | 4.723759e-84 | -0.529334 | 0.018918 | 3.546091e-162 |
| rt_Shared_room | -1.052854 | 0.084174 | 1.836512e-35 | -1.224459 | 0.042597 | 1.657163e-170 |
| pg_Condominium | 0.204447 | 0.033943 | 1.810152e-09 | 0.105307 | 0.028131 | 1.831822e-04 |
| pg_House | 0.075353 | 0.023378 | 1.274269e-03 | -0.045447 | 0.017957 | 1.140318e-02 |
| pg_Other | 0.295485 | 0.038645 | 2.394157e-14 | 0.060753 | 0.027637 | 2.796727e-02 |
| pg_Townhouse | -0.073508 | 0.049367 | 1.365396e-01 | -0.010397 | 0.045673 | 8.199294e-01 |
An interesting question arises around the relevance of the regimes. Are estimates for each variable across regimes statistically different? For this, the model object also calculates for us what is called a Chow test. This is a statistic that tests the null hypothesis that estimates from different regimes are undistinguishable. If we reject the null, we have evidence suggesting the regimes actually make a difference.
Results from the Chow test are available on the summary attribute, or we can extract them directly from the model object, which we will do here. There are two types of Chow test. First is a global one that jointly tests for differences between the two regimes:
m5.chow.joint(np.float64(328.86902143021393), np.float64(7.113548767598336e-64))The first value represents the statistic, while the second one captures the p-value. In this case, the two regimes are statistically different from each other. The next step then is to check whether each of the coefficients in our model differs across regimes. For this, we can pull them out into a table:
pandas.DataFrame(
# Chow results by variable
m5.chow.regi,
# Name of variables
index=m5.name_x_r,
# Column names
columns=["Statistic", "P-value"],
)| Statistic | P-value | |
|---|---|---|
| CONSTANT | 4.832180 | 2.793329e-02 |
| accommodates | 16.735685 | 4.296522e-05 |
| bathrooms | 22.671471 | 1.922004e-06 |
| bedrooms | 11.503786 | 6.945459e-04 |
| beds | 3.060313 | 8.022620e-02 |
| rt_Private_room | 0.740097 | 3.896298e-01 |
| rt_Shared_room | 3.308838 | 6.890820e-02 |
| pg_Condominium | 5.057283 | 2.452265e-02 |
| pg_House | 16.792503 | 4.169771e-05 |
| pg_Other | 24.409876 | 7.786847e-07 |
| pg_Townhouse | 0.880564 | 3.480471e-01 |
As we can see in the table, most variables do indeed differ across regimes, statistically speaking. This points to systematic differences in the data generating processes across spatial regimes.
13.4.3 Spatial dependence
As we have just discussed, SH is about effects of phenomena that are explicitly linked to geography and that hence cause spatial variation and clustering. This encompasses many of the kinds of spatial effects we may be interested in when we fit linear regressions. However, in other cases, our focus is on the effect of the spatial configuration of the observations, and the extent to which that has an effect on the outcome we are considering. For example, we might think that the price of a house not only depends on whether it is a townhouse or an apartment, but also on whether it is surrounded by many more townhouses than skyscrapers with more apartments. This, we could hypothesize, might be related to the different “look and feel” a neighborhood with low-height, historic buildings has as compared to one with modern high-rises. To the extent these two different spatial configurations enter differently the house price determination process, we will be interested in capturing not only the characteristics of a house, but also of its surrounding ones. This kind of spatial effect is fundamentally different from SH in that is it not related to inherent characteristics of the geography but relates to the characteristics of the observations in our dataset and, specially, to their spatial arrangement. We call this phenomenon by which the values of observations are related to each other through distance spatial dependence (Anselin 1988).
There are several ways to introduce spatial dependence in an econometric framework, with varying degrees of econometric sophistication (see (Anselin 2002) for a good overview). Common to all of them however is the way space is formally encapsulated: through spatial weights matrices (\(\mathbf{W}\)), which we discussed in Chapter 4. In this section, we consider three ways in which spatial dependence, through spatial weights matrices, can be incorporated in a regression framework. We begin with the “least invasive” one, where we only modify the set of independent variables, and the move into more substantial modifications of the baseline linear model.
13.4.3.1 Exogenous effects: The SLX model
Let us come back to the house price example we have been working with. So far, we have hypothesized that the price of a house rented in San Diego through Airbnb can be explained using information about its own characteristics as well as some relating to its location such as the neighborhood or the distance to the main park in the city. However, it is also reasonable to think that prospective renters care about the set of neighbors a house has, not only about the house itself, and would be willing to pay more for a house that was surrounded by certain types of houses, and less if it was located in the middle of other types. How could we test this idea?
When it comes to regression, the most straightforward way to introduce spatial dependence between the observations in the data is by considering not only a given explanatory variable, but also its spatial lag. Conceptually, this approach falls more within the area of spatial feature engineering, which embeds space in a model through the explanatory variables it uses rather than the functional form of the model, and which we delve into with more detail in Chapter 12. But we think it is interesting to discuss it in this context for two reasons. First, it provides “intellectual scaffolding” to learn the intuition of building spatial dependence into regression. And second, because it also illustrates how many of the techniques we cover in Chapter 12 can be embedded in a regression model (and, by extension, in other predictive approaches).
In our example case, in addition to including a dummy for the type of house (pg_XXX), we can also include the spatial lag of each type of house. This addition implies we are also including as explanatory factor of the price of a given house the proportion neighboring houses in each type. Mathematically, this implies estimating the following model:
\[ \log(P_i) = \alpha + \sum^{p}_{k=1}X_{ij}\beta_j + \sum^{p}_{k=1}\left(\sum^{N}_{j=1}w_{ij}x_{jk}\right)\gamma_k + \epsilon_i \]
where \(\sum_{j=1}^N w_{ij}x_{jk}\) represents the spatial lag of the \(k\)th explanatory variable. This can be stated in matrix form using the spatial weights matrix, \(\mathbf{W}\), as:
\[ \log(P_i) = \alpha + \mathbf{X}\beta + \mathbf{WX}\gamma + \epsilon \]
This splits the model to focus on two main effects: \(\beta\) and \(\gamma\). The \(\beta\) effect describes the change in \(y_i\) when \(X_{ik}\) changes by one. 1 The subscript for site \(i\) is important here: since we’re dealing with a \(\mathbf{W}\) matrix, it’s useful to be clear about where the change occurs.
Indeed, this matters for the \(\gamma\) effect, which represents the indirect association of a change in \(X_i\) with the house price. This can be conceptualized in two ways. First, one could think of \(\gamma\) as simply the association between the price in a given house and a unit change in its average surroundings. This is useful and simple. But this interpretation blurs where this change might occur. In truth, a change in a variable at site \(i\) will result in a spillover to its surroundings: when \(x_i\) changes, so too does the spatial lag of any site near \(i\). The precise size of the change in the lag will depend on the structure of \(\mathbf{W}\), and it can be different for every site it is connected with. For example, think of a very highly connected “focal” site in a row-standardized weight matrix. This focal site will not be strongly affected if a neighbor changes by a single unit, since each site only contributes a small amount to the lag at the focal site. Alternatively, consider a site with only one neighbor: its lag will change by exactly the amount its sole neighbor changes. Thus, to discover the exact indirect effect of a change \(y\) caused by the change at a specific site \(x_i\) you would need to compute the change in the spatial lag, and then use that as your change in \(X\). We will discuss this in the following section.
In Python, we can calculate the spatial lag of each variable whose name starts by pg_ by first creating a list of all of those names, and then applying pysal’s lag_spatial to each of them:
# Select only columns in `db` containing the keyword `pg_`
wx = (
db.filter(
like="pg_"
# Compute the spatial lag of each of those variables
)
.apply(
lambda y: weights.spatial_lag.lag_spatial(knn, y)
# Rename the spatial lag, adding w_ to the original name
)
.rename(
columns=lambda c: "w_"
+ c
# Remove the lag of the binary variable for apartments
)
.drop("w_pg_Apartment", axis=1)
)Once computed, we can run the model using OLS estimation because, in this context, the spatial lags included do not violate any of the assumptions OLS relies on (they are essentially additional exogenous variables):
# Merge original variables with the spatial lags in `wx`
slx_exog = db[variable_names].join(wx)
# Fit linear model with `spreg`
m6 = spreg.OLS(
# Dependent variable
db[["log_price"]].values,
# Independent variables
slx_exog.values,
# Dependent variable name
name_y="l_price",
# Independent variables names
name_x=slx_exog.columns.tolist(),
)As in the previous cases, printing the summary attribute of the model object would show a full report table. The variables we included in the original regression display similar behavior, albeit with small changes in size, and can be interpreted also in a similar way. To focus on the aspects that differ from the previous models here, we will only pull out results for the variables for which we also included their spatial lags:
# Collect names of variables of interest
vars_of_interest = (
db[variable_names].filter(like="pg_").join(wx).columns
)
# Build full table of regression coefficients
pandas.DataFrame(
{
# Pull out regression coefficients and
# flatten as they are returned as Nx1 array
"Coeff.": m6.betas.flatten(),
# Pull out and flatten standard errors
"Std. Error": m6.std_err.flatten(),
# Pull out P-values from t-stat object
"P-Value": [i[1] for i in m6.t_stat],
},
index=m6.name_x
# Subset for variables of interest only and round to
# four decimals
).reindex(vars_of_interest).round(4)| Coeff. | Std. Error | P-Value | |
|---|---|---|---|
| pg_Condominium | 0.1063 | 0.0222 | 0.0000 |
| pg_House | 0.0328 | 0.0157 | 0.0368 |
| pg_Other | 0.0862 | 0.0240 | 0.0003 |
| pg_Townhouse | -0.0277 | 0.0338 | 0.4130 |
| w_pg_Condominium | 0.5928 | 0.0690 | 0.0000 |
| w_pg_House | -0.0774 | 0.0319 | 0.0152 |
| w_pg_Other | 0.4851 | 0.0551 | 0.0000 |
| w_pg_Townhouse | -0.2724 | 0.1223 | 0.0260 |
The spatial lag of each type of property (w_pg_XXX) is the new addition. We observe that, except for the case of townhouses (same as with the binary variable, pg_Townhouse), they are all significant, suggesting our initial hypothesis on the role of the surrounding houses might indeed be at work here.
As an illustration, let’s look at some of the direct/indirect effects. The direct effect of the pg_Condominium variable means that condominiums are typically 11% more expensive (\(\beta_{pg\_{Condominium}}=0.1063\)) than the benchmark property type, apartments. More relevant to this section, any given house surrounded by condominiums also receives a price premium. But, since \(pg_{Condominium}\) is a dummy variable, the spatial lag at site \(i\) represents the percentage of properties near \(i\) that are condominiums, which is between \(0\) and \(1\).2 So, a unit change in this variable means that you would increase the condominium percentage by 100%. Thus, a \(.1\) increase in w_pg_Condominium (a change of ten percentage points) would result in a 5.92% increase in the property house price (\(\beta_{w_pg\_Condominium} = 0.6\)). Similar interpretations can be derived for all other spatially lagged variables to derive the indirect effect of a change in the spatial lag.
To compute the indirect change for a given site \(i\), you may need to examine the predicted values for its price. In this example, since we are using a row-standardized weights matrix with twenty nearest neighbors, the impact of changing \(x_i\) is the same for all of its neighbors and for any site \(i\). Thus, the effect is always \(\frac{\gamma}{20}\), or about \(0.0296\). However, it is interesting to consider this would not be the case for many other kinds of weights (like Kernel, Queen, Rook, DistanceBand, or Voronoi), where each observation has potentially a different number of neighbors. To illustrate this, we will construct the indirect effect for a specific \(i\) in the condominium group.
First, predicted values for \(y_i\) are stored in the predy attribute of any spreg model:
# Print first three predicted values
m5.predy[:3]array([[5.27285901],
[5.39966259],
[4.28834686]])To build new predictions, we need to follow the underlying equation of our model.
To illustrate the effect of a change in one of the values in a given location in other locations, we will switch one of the properties into the condominium category. Consider the third observation, which is the first apartment in the data:
# Print values for third observation for columns spanning
# from `pg_Apartment` to `pg_Townhouse`
db.loc[2, "pg_Apartment":"pg_Townhouse"]pg_Apartment 1
pg_Condominium 0
pg_House 0
pg_Other 0
pg_Townhouse 0
Name: 2, dtype: objectLet’s now make a copy of our data and change the value to magically turn the apartment into a condominium:
# Make copy of the dataset
db_scenario = db.copy()
# Make Apartment 0 and condo 1 for third observation
db_scenario.loc[2, ["pg_Apartment", "pg_Condominium"]] = [0, 1]We’ve successfully made the change:
db_scenario.loc[2, "pg_Apartment":"pg_Townhouse"]pg_Apartment 0
pg_Condominium 1
pg_House 0
pg_Other 0
pg_Townhouse 0
Name: 2, dtype: objectNow, we need to also update the spatial lag variates:
# Select only columns in `db_scenario` containing the keyword `pg_`
wx_scenario = (
db_scenario.filter(
like="pg"
# Compute the spatial lag of each of those variables
)
.apply(
lambda y: weights.spatial_lag.lag_spatial(knn, y)
# Rename the spatial lag, adding w_ to the original name
)
.rename(
columns=lambda c: "w_"
+ c
# Remove the lag of the binary variable for apartments
)
.drop("w_pg_Apartment", axis=1)
)And build a new exogenous \(\mathbf{X}\) matrix, including the a constant 1 as the leading column
slx_exog_scenario = db_scenario[variable_names].join(wx_scenario)Now, our new prediction (in the scenario where we have changed site 2 from an apartment into a condominium) can be computed by translating the model equation into Python code and plugging into it the simulated values we have just created:
# Compute new set of predicted values
y_pred_scenario = m6.betas[0] + slx_exog_scenario @ m6.betas[1:]Note the only difference between this set of predictions and the one in the original m6 model is that we have switched site 2 from apartment into condominium. Hence, every property which is not connected to site 2 (or is not site 2 itself) will be unaffected. The neighbors of site 2 however will have different predictions. To explore these, let’s first identify who is in this group:
print(knn.neighbors[2])[np.int64(772), np.int64(2212), np.int64(139), np.int64(4653), np.int64(2786), np.int64(1218), np.int64(138), np.int64(808), np.int64(1480), np.int64(4241), np.int64(1631), np.int64(3617), np.int64(2612), np.int64(1162), np.int64(135), np.int64(23), np.int64(5528), np.int64(3591), np.int64(407), np.int64(6088)]Now, the effect of changing site 2 from an apartment into a condominium is associated with the following changes to the predicted (log) price, which we calculate by substracting the new predicted values from the original ones and subsetting only to site 2 and its neighbors:
# Difference between original and new predicted values
(
y_pred_scenario
- m6.predy
# Subset to site `2` and its neighbors
).loc[[2] + knn.neighbors[2]]| 0 | |
|---|---|
| 2 | 0.106349 |
| 772 | 0.029642 |
| 2212 | 0.029642 |
| 139 | 0.029642 |
| 4653 | 0.029642 |
| 2786 | 0.029642 |
| 1218 | 0.029642 |
| 138 | 0.029642 |
| 808 | 0.029642 |
| 1480 | 0.029642 |
| 4241 | 0.029642 |
| 1631 | 0.029642 |
| 3617 | 0.029642 |
| 2612 | 0.029642 |
| 1162 | 0.029642 |
| 135 | 0.029642 |
| 23 | 0.029642 |
| 5528 | 0.029642 |
| 3591 | 0.029642 |
| 407 | 0.029642 |
| 6088 | 0.029642 |
We see the first row, representing the direct effect, is equal exactly to the estimate for pg_Condominium. For the other effects, though, we have only changed w_pg_Condominium by \(.03\) which roughly equates the marginal effect (w_pg_Condominium) divided by the weight of the spatial relationship between site 2 and every neighbor (in this case, \(\frac{1}{20}\) for every neighbor, but note if different neighbors had different cardinalities, this would differ).
Introducing a spatial lag of an explanatory variable, as we have just seen, is the most straightforward way of incorporating the notion of spatial dependence in a linear regression framework. It does not require additional changes, it can be estimated with OLS, and the interpretation is rather similar to interpreting non-spatial variables, so long as aggregate changes are required.
The field of spatial econometrics however is a much broader one and has produced over the last decades many techniques to deal with spatial effects and spatial dependence in different ways. Although this might be an over-simplification, one can say that most of such efforts for the case of a single cross-section are focused on two main variations: the spatial lag and the spatial error model. Both are similar to the case we have seen in that they are based on the introduction of a spatial lag, but they differ in the component of the model they modify and affect.
13.4.3.2 Spatial error
The spatial error model includes a spatial lag in the error term of the equation:
\[ \log{P_i} = \alpha + \sum_k \beta_k X_{ki} + u_i \]
\[ u_i = \lambda u_{lag-i} + \epsilon_i \]
where \(u_{lag-i} = \sum_j w_{i,j} u_j\). Although it appears similar, this specification violates the assumptions about the error term in a classical OLS model. Hence, alternative estimation methods are required. Pysal incorporates functionality to estimate several of the most advanced techniques developed by the literature on spatial econometrics. For example, we can use a general method of moments that account for heteroskedasticity (Arraiz et al. 2010):
# Fit spatial error model with `spreg`
# (GMM estimation allowing for heteroskedasticity)
m7 = spreg.GM_Error_Het(
# Dependent variable
db[["log_price"]].values,
# Independent variables
db[variable_names].values,
# Spatial weights matrix
w=knn,
# Dependent variable name
name_y="log_price",
# Independent variables names
name_x=variable_names,
)GM_Error_HetSimilarly as before, the summary attribute will return a full-featured table of results. For the most part, it may be interpreted in similar ways to those above. The main difference is that, in this case, we can also recover an estimate and inference for the \(\lambda\) parameter in the error term:
# Build full table of regression coefficients
pandas.DataFrame(
{
# Pull out regression coefficients and
# flatten as they are returned as Nx1 array
"Coeff.": m7.betas.flatten(),
# Pull out and flatten standard errors
"Std. Error": m7.std_err.flatten(),
# Pull out P-values from t-stat object
"P-Value": [i[1] for i in m7.z_stat],
},
index=m7.name_x
# Subset for lambda parameter and round to
# four decimals
).reindex(["lambda"]).round(4)| Coeff. | Std. Error | P-Value | |
|---|---|---|---|
| lambda | 0.6449 | 0.0187 | 0.0 |
13.4.3.3 Spatial lag
The spatial lag model introduces a spatial lag of the dependent variable. In the example we have covered, this would translate into:
\[ \log{P_i} = \alpha + \rho \log{P_{lag-i}} + \sum_k \beta_k X_{ki} + \epsilon_i \]
Although it might not seem very different from the previous equation, this model violates the exogeneity assumption, crucial for OLS to work. Put simply, this occurs when \(P_i\) exists on both “sides” of the equals sign. In theory, since \(P_i\) is included in computing \(P_{lag-i}\), exogeneity is violated. Similarly to the case of the spatial error, several techniques have been proposed to overcome this limitation, and Pysal implements several of them. In the example below, we use a two-stage least squares estimation (Anselin 1988), where the spatial lag of all the explanatory variables is used as instrument for the endogenous lag:
# Fit spatial lag model with `spreg`
# (GMM estimation)
m8 = spreg.GM_Lag(
# Dependent variable
db[["log_price"]].values,
# Independent variables
db[variable_names].values,
# Spatial weights matrix
w=knn,
# Dependent variable name
name_y="log_price",
# Independent variables names
name_x=variable_names,
)GM_LagAnd let’s summarize the coefficients in a table as before (usual disclaimer about the summary object applies):
# Build full table of regression coefficients
pandas.DataFrame(
{
# Pull out regression coefficients and
# flatten as they are returned as Nx1 array
"Coeff.": m8.betas.flatten(),
# Pull out and flatten standard errors
"Std. Error": m8.std_err.flatten(),
# Pull out P-values from t-stat object
"P-Value": [i[1] for i in m8.z_stat],
},
index=m8.name_z
# Round to four decimals
).round(4)| Coeff. | Std. Error | P-Value | |
|---|---|---|---|
| CONSTANT | 2.7440 | 0.0727 | 0.0000 |
| accommodates | 0.0698 | 0.0048 | 0.0000 |
| bathrooms | 0.1627 | 0.0104 | 0.0000 |
| bedrooms | 0.1604 | 0.0105 | 0.0000 |
| beds | -0.0365 | 0.0065 | 0.0000 |
| rt_Private_room | -0.4981 | 0.0151 | 0.0000 |
| rt_Shared_room | -1.1157 | 0.0366 | 0.0000 |
| pg_Condominium | 0.1073 | 0.0209 | 0.0000 |
| pg_House | -0.0004 | 0.0137 | 0.9766 |
| pg_Other | 0.1208 | 0.0215 | 0.0000 |
| pg_Townhouse | -0.0186 | 0.0323 | 0.5653 |
| W_log_price | 0.3416 | 0.0148 | 0.0000 |
Similarly to the effects in the SLX regression, changes in the spatial lag regression need to be interpreted with care. Here, W_log_price applies consistently over all observations and actually changes the effective strength of each of the \(\beta\) coefficients. Thus, it is useful to use predictions and scenario-building to predict \(y\) when changing \(X\), which allows you to analyze the direct and indirect components.
13.4.3.4 Other ways of bringing space into regression
We have covered here only a few ways to formally introduce space in a regression framework. There are however many other advanced spatial regression methods routinely used in statistics, data science, and applied analysis. For example, Generalized Additive Models (Gibbons, Overman, and Patacchini 2015; Wood 2006) have been used to apply spatial kernel smoothing directly within a regression function. Other similar smoothing methods, such as spatial Gaussian Process Models (Brunsdon, Fotheringham, and Charlton 2010) or Kriging, conceptualize the dependence between locations as smooth as well. Other methods in spatial regression that consider graph-based geographies (rather than distance/kernel effects) include variations on conditional autoregressive model, which examines spatial relationships at locations conditional on their surroundings, rather than as jointly co-emergent with them. Full coverage of these topics is beyond the scope of this book, however, though (Banerjee et al. 2008) provides a detailed and comprehensive discussion. We have not covered these (and other existing ones) not because we do not think are important or useful, far from it, but because we consider them a bit more advanced than the level at which we wanted to pitch the chapter.
Both sets of models we have introduced in here and others that exist but that we have not covered share the feature of embedding space as a “first class” citizen in the regression framework. In all these cases, we conceptualize space (e.g., through a spatial weights matrix) and modify the functional form of our original model in a way that recognizes the location of its observations when generating predictions or inference. This approach results in modifications of the modeling framework to accommodate geography. In the next chapter, we discuss a different perspective to embed space in our modeling efforts. Rather than injecting space through the functional form, we will do it through the variables we use to explain/predict the outcome of interest. In this case, we will be using geography to enrich our data before it is passed through a modeling framework.
13.5 Questions
- One common kind of spatial econometric model is the “Spatial Durbin Model,” which combines the SLX model with the spatial lag model. Alternatively, the “Spatial Durbin Error Model” combines the SLX model with the spatial error model. Fit a Spatial Durbin variant of the spatial models we have fit in this chapter.
- Do these variants improve the model fit?
- What happens to the spatial autocorrelation parameters (\(\rho\), \(\lambda\)) when the SLX term is added? Why might this occur?
- Fortunately for us, spatial error models recover the same estimates (asymptotically) as a typical OLS estimate, although their confidence intervals will change. Statistically, this occurs because OLS miscalculates when there is spatial correlation and/or spatial heteroskedasticity. How much do the confidence intervals change when the spatial error model is fit?
- One common justification for the SLX model (and the Spatial Durbin variants) is about omitted, spatially patterned variables. That is, if an omitted variable is associated with the included variables and is spatially patterned, then we can use the spatial structure of our existing variables to mimic the omitted variable. In our spatial lag model,
- what variables might we be missing that are important to predict the price of an Airbnb?
- would these omitted variables have a similar spatial pattern to our included variables? Why or why not?
- Where spatial regression models generally focus on how nearby observations are similar to one another, platial models focus on how observations in the same spatial group are similar to one another. These are often dealt with using multi-level or spatial mixed-effect models. When do these two ideas work together well? And, when might these disagree?
13.5.1 Challenge questions
The following discussions are a bit challenging but reflect extra enhancements to the discussions in the chapter that may solidify or enhance an advanced understanding of the material.
13.5.1.1 The random coast
In the section analyzing our naive model residuals, we ran a classic two-sample \(t\)-test to identify whether or not our coastal and non-coastal residential districts tended to have the same prediction errors. Often, though, it’s better to use straightforward, data-driven testing and simulation methods than assuming that the mathematical assumptions of the \(t\)-statistic are met.
To do this, we can shuffle our assignments to coast and not-coast, and check whether or not there are differences in the distributions of the observed residual distributions and random distributions. In this way, we shuffle the observations that are on the coast, and plot the resulting cumulative distributions.
Below, we run 100 simulated re-assignments of districts to either “coast” or “not coast,” and compare the distributions of randomly assigned residuals to the observed distributions of residuals. Further, we do this plotting by the empirical cumulative density function, not the histogram directly. This is because the empirical cumulative density function is usually easier to examine visually, especially for subtle differences.
The black lines in Figure XXX8XXX represent our simulations, and the colored patches below them represent the observed distribution of residuals. If the black lines tend to be on the left of the colored patch, then, the simulations (where prediction error is totally random with respect to our categories of “coastal” and “not coastal”) tend to have more negative residuals than our actual model. If the black lines tend to be on the right, then they tend to have more positive residuals. As a refresher, positive residuals mean that our model is under-predicting, and negative residuals mean that our model is over-predicting. Below, our simulations provide direct evidence for the claim that our model may be systematically under-predicting coastal price and over-predicting non-coastal prices.
n_simulations = 100
f, ax = plt.subplots(1, 2, figsize=(12, 3), sharex=True, sharey=True)
ax[0].hist(
coastal,
color=["r"] * 3,
alpha=0.5,
density=True,
bins=30,
label="Coastal",
cumulative=True,
)
ax[1].hist(
not_coastal,
color="b",
alpha=0.5,
density=True,
bins=30,
label="Not Coastal",
cumulative=True,
)
for simulation in range(n_simulations):
shuffled_residuals = m1.u[numpy.random.permutation(m1.n)]
random_coast, random_notcoast = (
shuffled_residuals[is_coastal],
shuffled_residuals[~is_coastal],
)
if simulation == 0:
label = "Simulations"
else:
label = None
ax[0].hist(
random_coast,
density=True,
histtype="step",
color="k",
alpha=0.05,
bins=30,
label=label,
cumulative=True,
)
ax[1].hist(
random_coast,
density=True,
histtype="step",
color="k",
alpha=0.05,
bins=30,
label=label,
cumulative=True,
)
ax[0].legend()
ax[1].legend()
plt.tight_layout()
plt.show()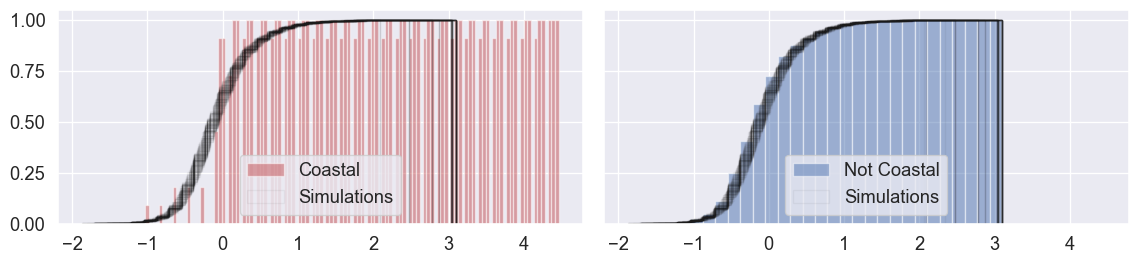
13.5.1.2 The K-neighbor correlogram
Further, it might be the case that spatial dependence in our mispredictions only matters for sites that are extremely close to one another, and it decays quickly with distance. To investigate this, we can examine the correlation between each site’s residual and the average of the \(k\)th nearest neighbors’ residuals, increasing \(k\) until the estimate stabilizes. This main idea is central to the geostatistical concept, the correlogram, which gives the correlation between sites of an attribute being studied as distance increases.
One quick way to check whether or not what we’ve seen is unique or significant is to compare it to what happens when we just assign neighbors randomly. If what we observe is substantially different from what emerges when neighbors are random, then the structure of the neighbors embeds a structure in the residuals. We won’t spend too much time on this theory specifically, but we can quickly and efficiently compute the correlation between our observed residuals and the spatial lag of an increasing \(k\)-nearest neighbor set:
correlations = []
nulls = []
for order in range(1, 51, 5):
knn.reweight(
k=order, inplace=True
) # operates in place, quickly and efficiently avoiding copies
knn.transform = "r"
lag_residual = weights.spatial_lag.lag_spatial(knn, m1.u)
random_residual = m1.u[numpy.random.permutation(len(m1.u))]
random_lag_residual = weights.spatial_lag.lag_spatial(
knn, random_residual
) # identical to random neighbors in KNN
correlations.append(
numpy.corrcoef(m1.u.flatten(), lag_residual.flatten())[0, 1]
)
nulls.append(
numpy.corrcoef(m1.u.flatten(), random_lag_residual.flatten())[
0, 1
]
)And use the code below to generate Figure XXX9XXX:
plt.plot(range(1, 51, 5), correlations)
plt.plot(range(1, 51, 5), nulls, color="orangered")
plt.hlines(
numpy.mean(correlations[-3:]),
*plt.xlim(),
linestyle=":",
color="k"
)
plt.hlines(
numpy.mean(nulls[-3:]), *plt.xlim(), linestyle=":", color="k"
)
plt.text(
s="Long-Run Correlation: ${:.2f}$".format(
numpy.mean(correlations[-3:])
),
x=25,
y=0.3,
)
plt.text(
s="Long-Run Null: ${:.2f}$".format(numpy.mean(nulls[-3:])),
x=25,
y=0.05,
)
plt.xlabel("$K$: number of nearest neighbors")
plt.ylabel(
"Correlation between site \n and neighborhood average of size $K$"
)
plt.show()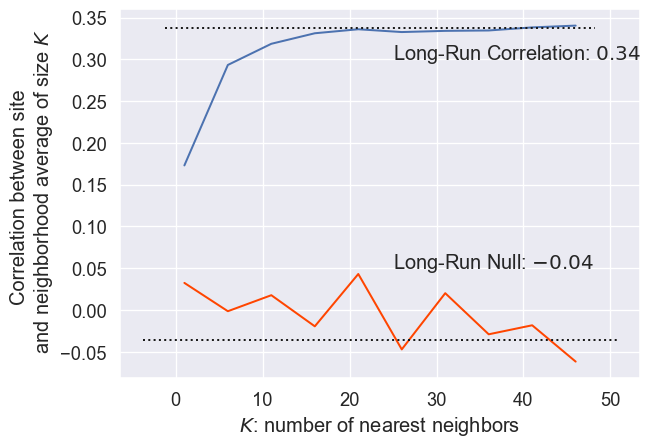
Clearly, the two curves are different. The observed correlation reaches a peak around \(r=.34\) when around 20 nearest listings are used. This means that adding more than 20 nearest neighbors does not significantly change the correlation in the residuals. Further, the lowest correlation is for the single nearest neighbor, and correlation rapidly increases as more neighbors are added close to the listing. Thus, this means that there does appear to be an unmeasured spatial structure in the residuals, since they are more similar to one another when they are near than when they are far apart. Further, while it’s not shown here (since computationally, it becomes intractable), as the number of nearest neighbors gets very large (approaching the number of observations in the dataset), the average of the \(k\)th nearest neighbors’ residuals goes to zero, the global average of residuals. This means that the correlation of the residuals and a vector that is nearly constant begins to approach zero.
The null correlations, however, use randomly chosen neighbors (without reassignment). Thus, since sampling is truly random in this case, each average of \(k\) randomly chosen neighbors is usually zero (global mean). So, the correlation between the observed residual and the average of \(k\) randomly chosen residuals is also usually zero. Thus, increasing the number of randomly chosen neighbors does not significantly adjust the long-run average of zero. Taken together, we can conclude that there is distinct positive spatial dependence in the error. This means that our over- and under-predictions are likely to cluster.
13.6 Next steps
For additional reading on the topics covered in this chapter, please consult the following resources:
For a more in-depth discussion of the fundamentals of spatial econometrics and applications in both GUI and command-line software, consult:
Anselin, Luc and Sergio Rey. 2014. Modern Spatial Econometrics in Practice: A Guide to GeoDa, GeoDaSpace, and Pysal. GeoDa Press.
For additional mathematical detail and more extensive treatment of space-time models, consult:
Cressie, Noel and Christopher N. Wikle. 2011. Statistics for Spatio-Temporal Data. Singapore: Wiley Press.
For an alternative perspective on regression and critique of the spatial econometric perspective, consider:
Gibbons, Stephen and Henry G. Overman. 2012. “Mostly Pointless Spatial Econometrics.” Journal of Regional Science 52: 172-191.
And for a useful overview of the discussions around multi-level modeling, with references therein to further resources, consider:
Owen, Gwilym, Richard Harris, and Kelvyn Jones. “Under Examination: Multilevel models, geography and health research.” Progress in Human Geography 40(3): 394-412.
Since we use the log price as the dependent variable, our \(\beta\) coefficients can be interpreted as the percentage change in the price associated with a unit change in the explanatory variable.↩︎
Discover this for yourself: what is the average of
numpy.array([True, True, True, False, False, True)]?↩︎